BigQueryのデータを自然言語で分析するAIデータアシスタントを作った話
どうも、takeisa です。
最近暖かくなってきたと思ったらまた寒かったり、寒暖差が厳しいです。健康第一でいきましょう。
今回は以前から気になっていた Text-to-SQL を、実務で感じていた課題を解決するかたちで試してみました。GCPのVertex AI(Gemini)を使い、BigQueryのデータに自然言語で質問できるAIデータアシスタントを作った話です。
実務で作っておけばよかったです、ごめんなさい。
なぜ作ったか
データ基盤を整えても「使いこなせる人が限られる」という課題はわりとあるあるかもしれません。実体験で以下のような課題がありました。
- (プロダクトエンジニア時代に)開発中の問い合わせ対応や障害の影響範囲調査で、複雑な複合条件のSQLをその場で書くのが辛かった。半日以上溶かすことも。。
- ダッシュボードやKPIの数字を見ても「なぜそうなったか」は別で補足説明が必要だった。
- データの民主化を掲げながらも、SQLへの抵抗感からBQを利用するメンバーが限られていた。
- Bizメンバーから「分析要件を決める前にアナリストと気軽に壁打ちしたい」という声もあった。
これらのデータへのアクセス体験の問題に対して、自然言語でBigQueryに質問できるAIアシスタントを作ってみることにしました。
作ったもの
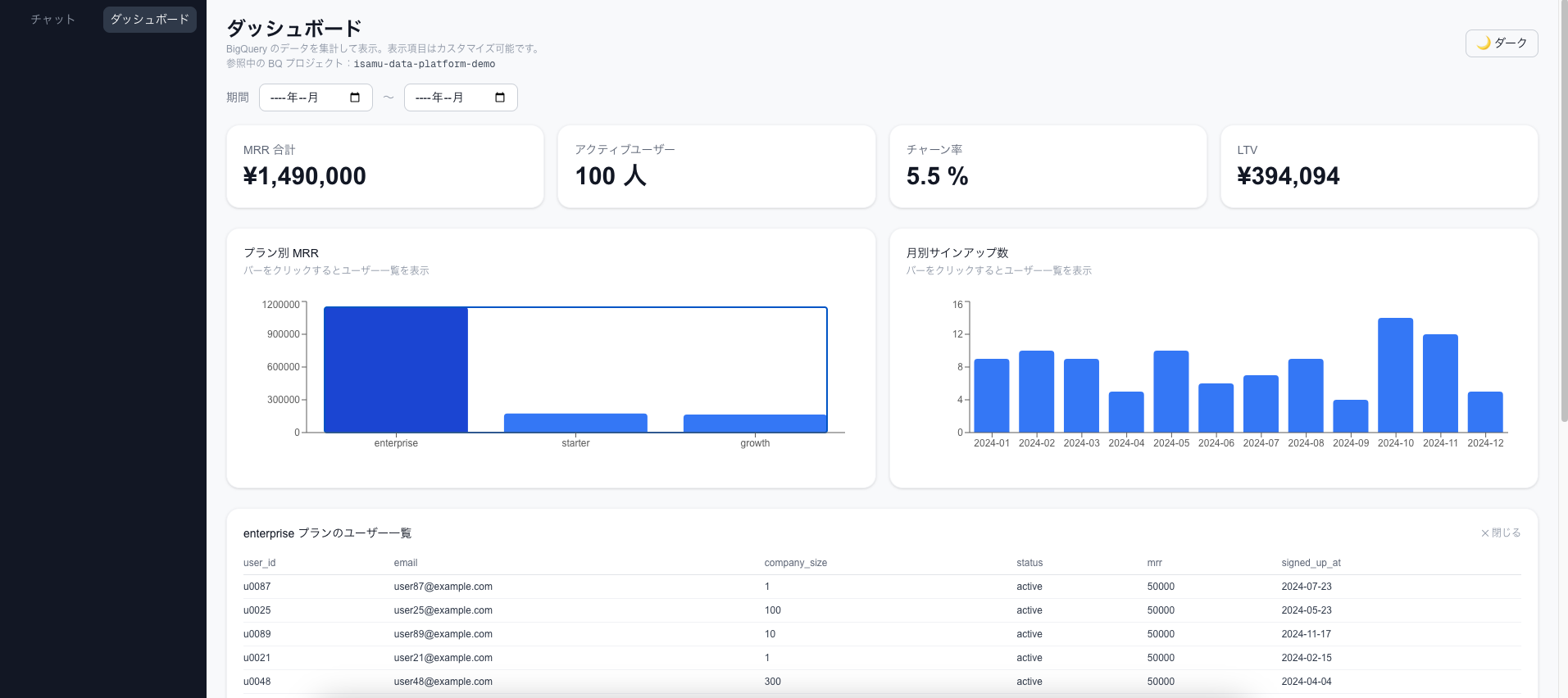
BigQueryに蓄積したデータに自然言語で質問できるAIアシスタントと、KPIダッシュボードを作りました。
主な機能
| 機能 | 説明 |
|---|---|
| AIチャット | 自然言語で質問 → GeminiがSQLを生成 → BigQueryを実行して回答 |
| ダッシュボード | MRR・チャーン率・LTV・サインアップ数をグラフで表示 |
| ドリルダウン | グラフのバーをクリックするとユーザー一覧を表示 |
| 期間フィルタ | ダッシュボードの集計期間を月単位で指定 |
| CSVダウンロード | チャットの回答をCSVで保存 |
| チャット履歴 | セッションごとの質問履歴をBigQueryに保存・復元 |
| BQプロジェクト表示 | 参照中のBigQueryプロジェクトIDをヘッダーに表示 |
| 利用可能なデータ表示 | ai_chat: true ラベルが付いたテーブルのスキーマをサイドバーに表示 |
デモ
実際にGCPにリソースを構築して、BQにサンプルデータを入れています。
https://ai-data-platform-frontend-541263482647.asia-northeast1.run.app/
チャット画面
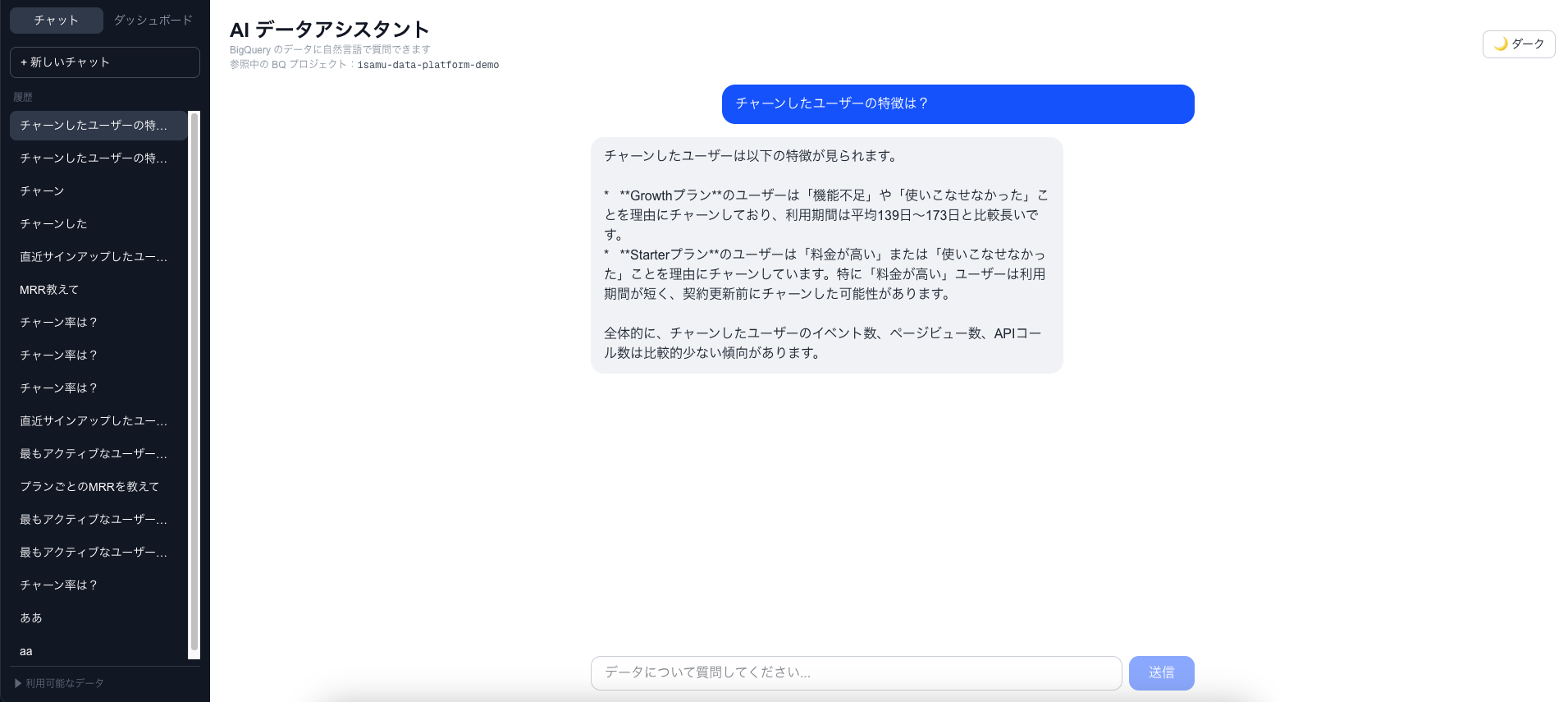
ダッシュボード画面
アーキテクチャ
ユーザー
↓
Next.js(Cloud Run) ← フロントエンド
↓
FastAPI(Cloud Run) ← バックエンドAPI
↓ ↓
Gemini API BigQuery ← LLM / データウェアハウス
↑
dbt(mart層) ← データ変換
↑
raw.* テーブル ← 生データ
フロントエンドとバックエンドはそれぞれCloud Runにデプロイし、バックエンドがVertex AI経由でGeminiを呼び出しながらBigQueryを操作する構成です。BigQueryのデータはrawテーブルに生データを蓄積し、dbtでmartテーブルに変換して集計・分析に使っています。
Vertex AIについて
Vertex AIはGoogleが企業向けのAIアプリケーション開発において公式に推奨しているプラットフォームで、IAMによるアクセス制御やVPCとの統合など、本番運用を見据えたセキュリティ・ガバナンス面が充実しています。
dbt Coreについて
データ変換にはdbt Cloudではなくdbt Coreを使用しています。dbt Cloudはスケジュール実行やGUIの管理画面が便利な一方、有料プランが必要です。今回は小~中規模のデータ基盤を想定しているのとデモ用途のためdbt Coreをローカルで実行し、本番運用時はCloud Scheduler + Cloud Run Jobでの自動化を想定した構成にしています。
使用したGCP API
| API | 用途 |
|---|---|
| BigQuery | データウェアハウス |
| BigQuery Storage | 高速データ読み取り |
| Cloud Run | バックエンド・フロントエンドのホスティング |
| Cloud Build | Dockerイメージのビルド |
| Artifact Registry | Dockerイメージの保存 |
| Vertex AI | Gemini APIの呼び出し |
| Cloud Storage | データファイルの保存 |
| Cloud Scheduler | dbt定期実行(本番運用時) |
実装のポイント
1. Geminiへのプロンプト設計
GeminiへのリクエストはSQL生成と回答生成の2段階に分けています。
まずSQL生成では、BigQueryのスキーマ情報と会話履歴をプロンプトに含めてSQLだけを返すよう指示します。データと無関係な質問には NOT_A_QUERY を返すルールも設けています。
sql_prompt = f"""
あなたはBigQueryのSQLエキスパートです。
以下のスキーマを参照して、ユーザーの質問に答えるBigQuery SQLを生成してください。
{SCHEMA_CONTEXT}
ルール:
- SQLのみを返してください(説明不要)
- チャーン率・LTV・MRRなどビジネス指標に関する質問はすべてSQLを生成する
- 完全に無関係な質問(天気・料理・雑談など)の場合のみ NOT_A_QUERY を返す
質問: {req.message}
"""
SQL実行後、取得結果をそのままGeminiに渡して日本語の回答を生成します。この2段階構成により、LLMが直接データを返すのではなくBigQueryが正しい数値を保証する設計になっています。
2. Thinking モードの使い分け
Gemini 2.5 FlashにはThinking(推論)モードがあり、thinking_budget で制御できます。
| ステップ | Thinking | 理由 |
|---|---|---|
| SQL生成 | 有効(-1) | 質問の解釈・複雑なクエリの組み立てに推論が必要 |
| 回答生成 | 無効(0) | 取得済みデータを日本語で説明するだけなので不要 |
SQL生成のみ有効にすることで、精度を保ちながらコストと速度のバランスを取っています。
GEMINI_SQL_CONFIG = GenerateContentConfig( thinking_config=ThinkingConfig(thinking_budget=-1) ) GEMINI_ANSWER_CONFIG = GenerateContentConfig( thinking_config=ThinkingConfig(thinking_budget=0) )3. チャットとダッシュボードのデータ整合性
当初ダッシュボードとチャットが異なるテーブルを参照していたため、チャーン率などの数値が一致しない問題が発生しました。dbtで mart.kpi_summary を作成し、両方が同じテーブルを参照するよう統一しました。
チャット ─┐
├─→ mart.kpi_summary(dbtで管理)
ダッシュボード─┘
数値の一貫性はデモの信頼性に直結するため、単一のmartテーブルを正とする設計は重要なポイントです。
4. dbt でのmart層設計
チャーン率・LTV・MRRをまとめた kpi_summary モデルをdbtで管理しています。
select
sum(case when status = 'active' then mrr else 0 end) as total_mrr,
round(safe_divide(countif(status = 'churned'), count(*)) * 100, 1) as churn_rate_pct,
round(safe_divide(avg(case when status = 'active' then mrr end),
safe_divide(countif(status = 'churned'), count(*))), 0) as ltv
from subscriptions
dbt run を実行するだけで全KPIが更新される構成で、本番ではCloud Scheduler + Cloud Run Jobで定期実行を想定しています。
5. レートリミット
デモ公開にあたり、LLMの呼び出しコスト爆発を防ぐためslowapi を使って /chat エンドポイントに制限をかけています。
@limiter.limit("10/day")
async def chat(request: Request, req: ChatRequest):
IPアドレスベースで1日10回までに制限しています。本番ではユーザー認証と組み合わせてユーザーIDベースの制限に切り替えることを推奨します。
6. Gemini Flash のリージョンをglobalに設定
Vertex AI経由でGeminiを呼び出す際、リージョンを global に設定しています。
gemini = genai.Client(vertexai=True, project=PROJECT_ID, location="global")
asia-northeast1 を指定するとGemini 2.5 Flashが利用できませんでした。global にすることでGoogleが自動的に最適なリージョンにルーティングしてくれるため、モデルの可用性とレイテンシのバランスが取れた設定です。
セキュリティ・ガバナンス
アクセス制御
今回実装したデモでは制御していませんが、
本番運用では Cloud Run 認証と IAP(Identity-Aware Proxy)を組み合わせた二重構造を想定しています。
ユーザー → IAP(Googleログイン) → フロントエンド → バックエンド
↑
フロントエンドSAのみ許可
IAPを通過した場合だけCloud Runに届く構成にすることで、URLを直接叩いても弾かれます。アクセス権限はGoogleグループ単位で管理できるため、メンバーの追加・削除はグループ側で完結しGCPのIAMを都度触る必要がありません。
gcloud run services add-iam-policy-binding ai-data-platform-frontend \ --member="group:your-team@googlegroups.com" \ --role="roles/run.invoker"バックエンドの保護
バックエンドはフロントエンドのサービスアカウントからのみ呼び出せるよう制限することで、バックエンドのURLを直接叩かれても403を返す構成にできます。今回のデモはバックエンドも全公開のため、レートリミットで最低限のコスト保護をしています。
参照テーブルのガバナンス
ai_chat: true ラベルが付いたテーブルのみGeminiのスキーマ情報として渡す設計にしています。機密性の高いテーブルはラベルを付けなければAIに参照させないため、データガバナンスの観点でも管理しやすい構成です。
コスト管理
Geminiのコスト
Geminiの呼び出しはSQL生成と回答生成の2回/リクエスト発生します。Thinking モードはSQL生成のみ有効にしており、回答生成は無効にすることでコストと精度のバランスを取っています。Thinking モードを両方有効にすると処理トークン数が増えるため、用途に応じた使い分けが重要なようです。
この辺のトークン管理はちゃんとしないとコストが跳ね上がりそうなので、また別の記事にまとめてみようと考えています。
BigQueryのコスト
BigQueryはスキャンしたデータ量に応じた課金のため、生データに直接クエリを投げ続けると想定外のコストになりえます。dbtでmartテーブルに事前集計しておくことで、ダッシュボードやチャットが参照するデータ量を最小限に抑えています。
Cloud Runのコスト
Cloud Runはリクエストベースの課金で、アイドル時はほぼゼロです。デモ規模であれば無料枠内に収まることがほとんどです。
レートリミット
/chat エンドポイントに1日10回/IPの制限をかけています。
予算アラートの設定
GCPの予算アラートを設定しておくことで、想定外のコスト増に早期に気づけます。
GCPコンソール → お支払い → 予算とアラート → 予算を作成
予算の閾値(50%・90%・100%)に達した際にメール通知が届くよう設定しています。Geminiの呼び出しが異常に増えた場合やBigQueryのスキャン量が跳ね上がった場合の保険として設定しています。
BQエージェントとの違い
https://x.com/yoshitake_l/status/2031278027813040153?s=20
先日私もリツイートしたこちらのBigQuery のエージェント機能(Conversational Analytics)。現在まだプレビュー中ですが、こちらも自然言語でクエリできるようです。
今回自作したものとの違い(自分の理解)
| 観点 | BQエージェント(公式) | 今回自作したもの |
|---|---|---|
| 機能 | 自然言語→SQL・可視化・データ探索 | 自然言語→SQL・グラフ表示・CSVダウンロード |
| UI | GCPコンソール上。モバイルに最適化されていない。 | 独自のチャットUI・ダッシュボード。モバイル対応済み。 |
| カスタマイズ | できそう。用語集などでドメイン知識を教えられる。 | できる。プロンプト・スキーマ制御・UIを自由に設計可能。 |
| 参照テーブルの制御 | 制御可能 | ラベルで公開範囲を細かく制御 |
| 既存システムへの組み込み | 難しい | APIベースのため組み込みやすい |
| 導入コスト | 高い(導入だけなら中。データ整備も込みだと高) | 高い(導入だけなら中。データ整備も込みだと高) |
| 運用コスト | 中 | 中 |
| ガバナンス | GCP標準のIAM | 独自実装+GCP IAMの組み合わせ |
自作の強みとしては、UIUXのカスタマイズ性の高さという所感です。
どちらも分析の精度を上げるためにはデータ基盤で信頼できるデータの準備とメタデータの管理をしっかり行う必要がありますね。
気づき
Vertex AIを利用してアプリからGemini 2.5 Flashを利用するAIプロダクトを作ってみました。
まず、関連情報を調べていて改めてText-To-SQL の手段は各DWH系のサービスでスタンダードになってきているなというのを実感しました。作ってみて、周辺知識や他にブログに書きたいネタもいくつか出てきたので、また別の記事で書いていきます。
また、プロダクト開発と同じではありますが、特にデータを扱うプロダクトなのでセキュリティ・ガバナンス、コスト、運用を考慮した設計は重要ですね。
今後やりたいこと
今回自作したAIデータアシスタントでAIデータ分析の基盤ができました。
今後やってみたいこととしては以下を考えています。
- AIデータ分析の精度を高める為のデータ基盤構築や整備
- dbt でのデータ品質やメタデータの管理
- ユーザーのユースケースやドメインに特化したUIUXを備えたAIデータアシスタントを提供
- ADK を利用したマルチエージェント化
- 友人に教えてもらったやつ
- 今はGemini 2.5 Flash を利用した単一エージェントを利用していますが、ADK を利用すると分析の精度が向上するらしい。設計や管理が複雑になるのでゆくゆくやってみたい。
ここまで読んでいただきありがとうございます。
最後に宣伝になりますが、2026年からフリーランスのデータエンジニア / プロダクトエンジニアとして活動しています。
データ基盤の構築や改善、AI活用、プロダクト開発など課題があればお気軽にご連絡ください。